
Knowledge graphs transform scattered information into interconnected, semantically rich data. They represent entities, relationships, and context, making it possible to reason across domains rather than handling isolated tables or documents. The ontology provides the shared vocabulary – but in practice, the real challenge is turning heterogeneous data into RDF.
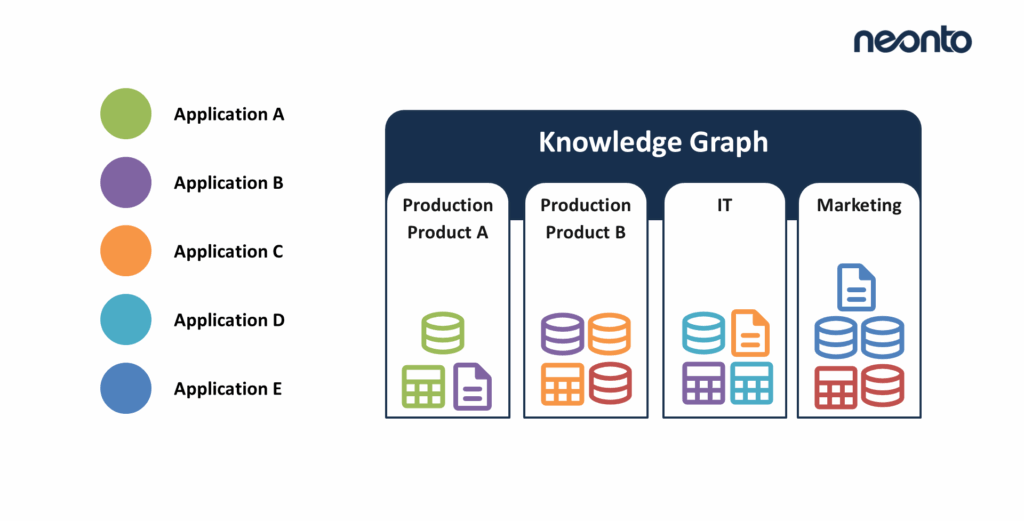
This challenge is universal: onboarding CSV dumps from ERP systems, consuming JSON from REST APIs, ingesting XML from legacy partners, synchronizing events from streaming pipelines, or converting relational schemas. Every source comes with its quirks, and RDF systems expect normalized, semantic triples. The question becomes: How can we instantiate our ontology efficiently, repeatably, and at scale?
Modern enterprises rarely deal with clean, uniform datasets. Instead, they operate on heterogeneous data that evolves over time, spans organizational boundaries, and reflects different modeling assumptions. Turning this heterogeneous data into consistent Knowledge Graphs is therefore not a one-off task, but a continuous engineering effort.
The Data Integration Problem: Data Variety Meets Semantic Rigor
Integrating heterogeneous data requires more than scripting. We need repeatable, auditable transformations that link raw data to ontology terms. CSV columns must become predicates. JSON arrays must be navigated with paths. XML hierarchies need to be flattened or preserved. SQL tables need URI templates and join logic to enable robust Data Ingestion pipelines.
Without a structured approach, pipelines become brittle and opaque. Ontology changes ripple into half-forgotten scripts. Teams duplicate logic. Debugging becomes guesswork. A declarative layer is needed to keep semantics separate from execution mechanics.
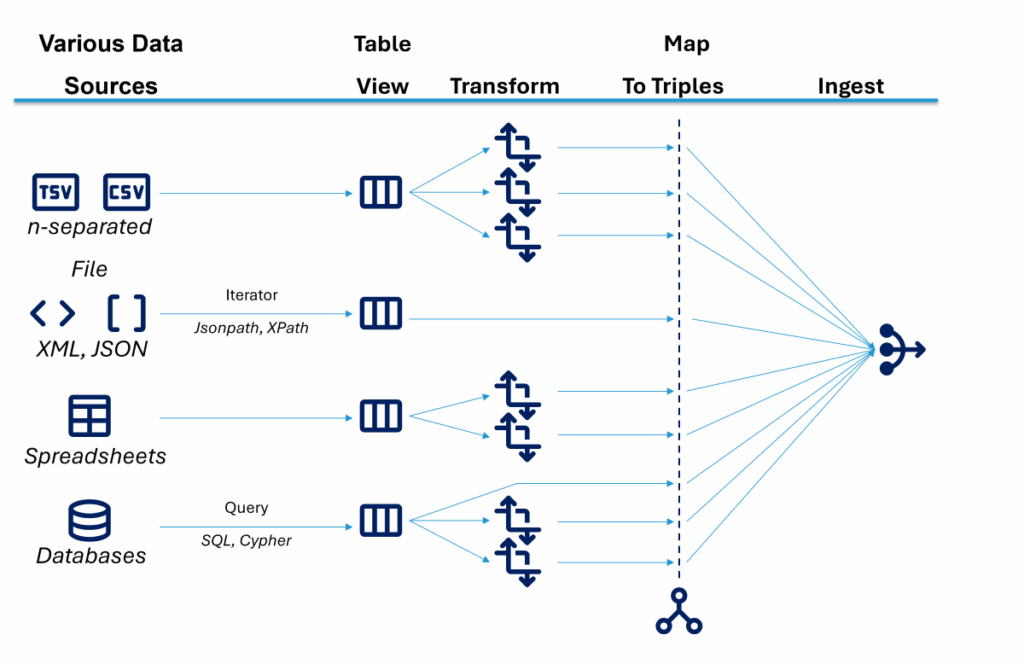
What makes this problem particularly challenging is that heterogeneous data often changes independently of the ontology. New fields appear, formats evolve, and source systems are replaced, all while downstream Knowledge Graphs must remain stable and trustworthy.
Two Architectural Paths: Imperative Code vs. Mapping Languages
Imperative pipelines rely on custom code written in Python or Java to parse inputs and emit RDF. They offer fine-grained control but tangle data logic with semantic logic. Over time, they can become hard to maintain, reuse, or adapt to changing ontologies.
Declarative mapping languages describe what the RDF should look like, not how to generate it. Execution engines process these specifications automatically. This separation improves reusability, testability, clarity, and alignment with the ontology.
From a lifecycle and DataOps perspective, declarative mappings are easier to version, review, lint, and test. They work well with virtual graphs, enabling queries over the source while postponing full materialization.
For these reasons, we generally prefer mapping languages for the transformation layer, while still allowing imperative preprocessing for special cases.
Mapping Languages: R2RML vs RML vs YARRRML
Mapping languages function similarly to transformation languages like XSLT: instead of step‑by‑step control flow, you define rules that match patterns in the source and produce RDF triples accordingly.
A brief landscape:
- R2RML: W3C recommendation for mapping relational databases to RDF.
- RML: An extension of R2RML supporting CSV, JSON, XML, and other formats.
- YARRRML: A human‑friendly YAML syntax that compiles into RML.
Where R2RML is SQL-centric, RML covers multi-format ecosystems. YARRRML lowers the barrier to authoring complex RML mappings.
YARRRML: Making Data Ingestion and Mappings Author‑Friendly
YARRRML exists to make knowledge graph mappings easier to read and write. The YAML format reduces verbosity, supports indentation, and keeps the structure clear. Under the hood, YARRRML transforms into RML, ensuring interoperability with mapping engines.
Example: Mapping CSV to RDF with YARRRML
Let’s take a simple CSV:
ID;FirstName;LastName;Email
1;Ada;Lovelace;ada@example.org
2;Alan;Turing;alan@example.orgWe want to generate simple RDF for schema:Person instances.
prefixes:
ex: http://example.com#
mappings:
persons:
sources:
- access: persons.csv
referenceFormulation: csv
delimiter: ;
s: ex:person_$(ID)
po:
- p: rdf:type
o: schema:Person
- p: schema:givenName
o: $(FirstName)This compiles to RML, which engines can execute to produce RDF. The screenshot below shows how much more boilerplate and how much worse the readability of the same logic would be in RML.
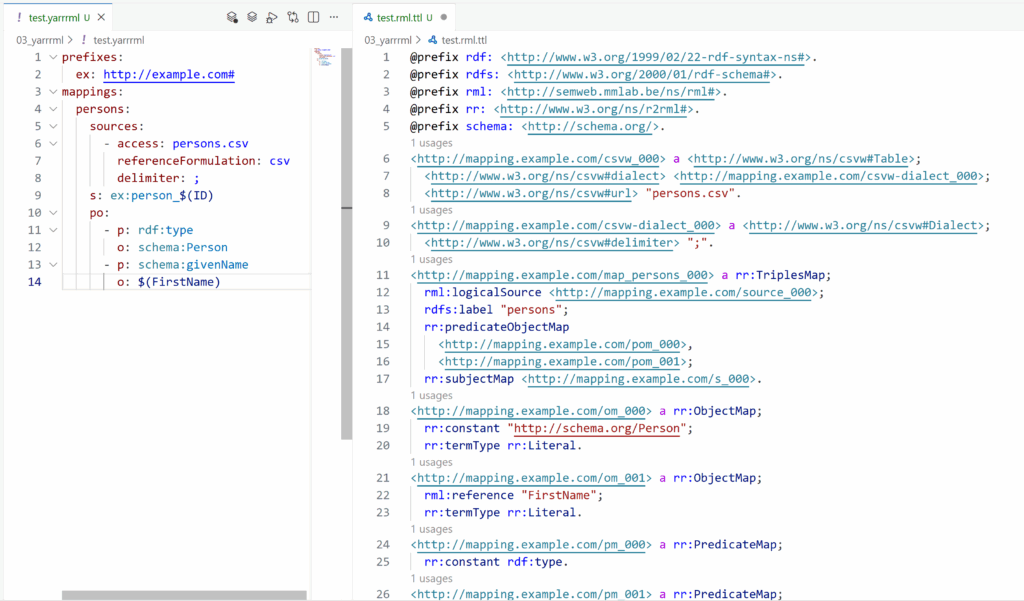
Tooling in the RML Ecosystem
Morph‑KGC
Morph‑KGC is a modern, efficient, and flexible R2RML/RML engine designed for materializing knowledge graphs from multiple data sources. It focuses on:
- high performance
- compatibility with RML and YARRRML
- easy configuration through simple YAML
- clean integration with Python and data engineering workflows.
A basic Morph‑KGC configuration might look like:
mappings: "mappings.rml.ttl"
output:
format: "turtle"
file: "output.ttl"
sources:
people:
type: csv
location: "persons.csv"Running Morph‑KGC materializes the RDF with minimal overhead.
RMLStreamer
For large‑scale workloads or continuous ingestion, RMLStreamer builds on Apache Flink. It executes RML mappings in distributed or streaming contexts, enabling near‑real‑time generation of knowledge graph fragments from high‑volume inputs.
Neonto editor
During the development phase, tools like the neonto editor help design and refine mappings visually, reducing trial‑and‑error and bridging the gap between domain experts and engineers.
Why Morph‑KGC + YARRRML Works Well
This combination offers a practical balance:
- YARRRML provides human‑friendly mapping design.
- RML ensures interoperability and long-term stability.
- Morph‑KGC materializes RDF quickly and consistently.
- RMLStreamer scales when workloads grow.
- Everything remains version-controlled, testable, and reproducible.
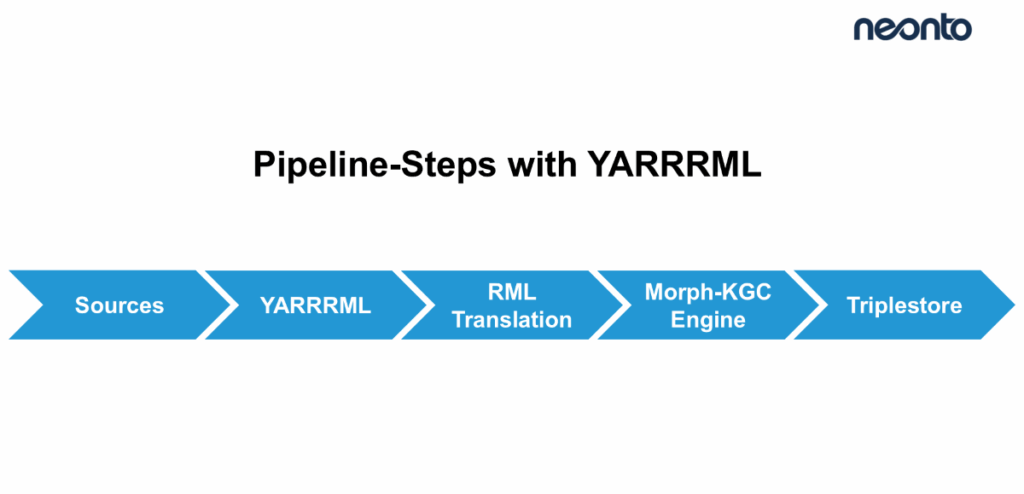
As a result, RML-based pipelines provide a robust foundation for scalable Data Ingestion, even as data volume, velocity, and variety increase. Together, they create a sustainable, maintainable, and transparent data to knowledge graph pipeline.
Putting Everything Together
A robust workflow might look like this:
- Model your domain with an ontology
- Inventory your data sources
- Write mappings in YARRRML
- Convert to RML (morph-kgc can also directly use YARRRML files)
- Use Morph‑KGC to materialize the first RDF graph
- Validate using SHACL
- Automate everything in CI/CD
Want to learn how to build production-ready ETL pipelines with YARRRML? Book a call with us.